
Snowbricks & Dataflake
The most strategic of scope creep

TL;DR
Snowflake is moving into processing. Databricks is moving into storage.
The two hottest data companies in the world are looking more and more similar to one another, with increasingly overlapping offerings and ambitions.
The stage is being set for quite the competitive dynamic, one that is reminiscent of previous-gen enterprise giants SAP & Oracle.
Snow & Bricks
Unless you’re living under a rock, you know that Snowflake and Databricks are two of the hottest companies in data land right now.
While Snowflake has been a household name in data circles for awhile, it was the company’s 2020 IPO that thrusted them into the mainstream, after an impressive up-and-to-the-right trajectory.
Databricks isn’t far behind — having raised at a $28 billion valuation earlier this year, they’re said to be another likely IPO candidate.
These companies started off in fairly distinct markets—what they were initially known for, at their cores, is pretty different:
Snowflake is the data warehouse company
Databricks is the Spark company
As they’ve matured, they’ve been expanding their offerings and creeping into one another’s space—and their visions of what they’re going after sound nearly identical.

This a very interesting and under-discussed competitive dynamic that I can’t say I’ve come across very often. Let’s dig in.
How it started:
Snowflake started as a Data Warehouse company.
As I wrote in the history section of The Generalist’s Snowflake S-1 Club report, Snowflake was founded in 2012 by ex-Oracle database architects who had a vision of building a cloud-native data warehouse from the ground up.
The market was ripe, the timing was right, and the company has executed near-flawlessly: fast-forward nine years and they’re doing over $500M a year in revenue and sitting at a $70B market cap.
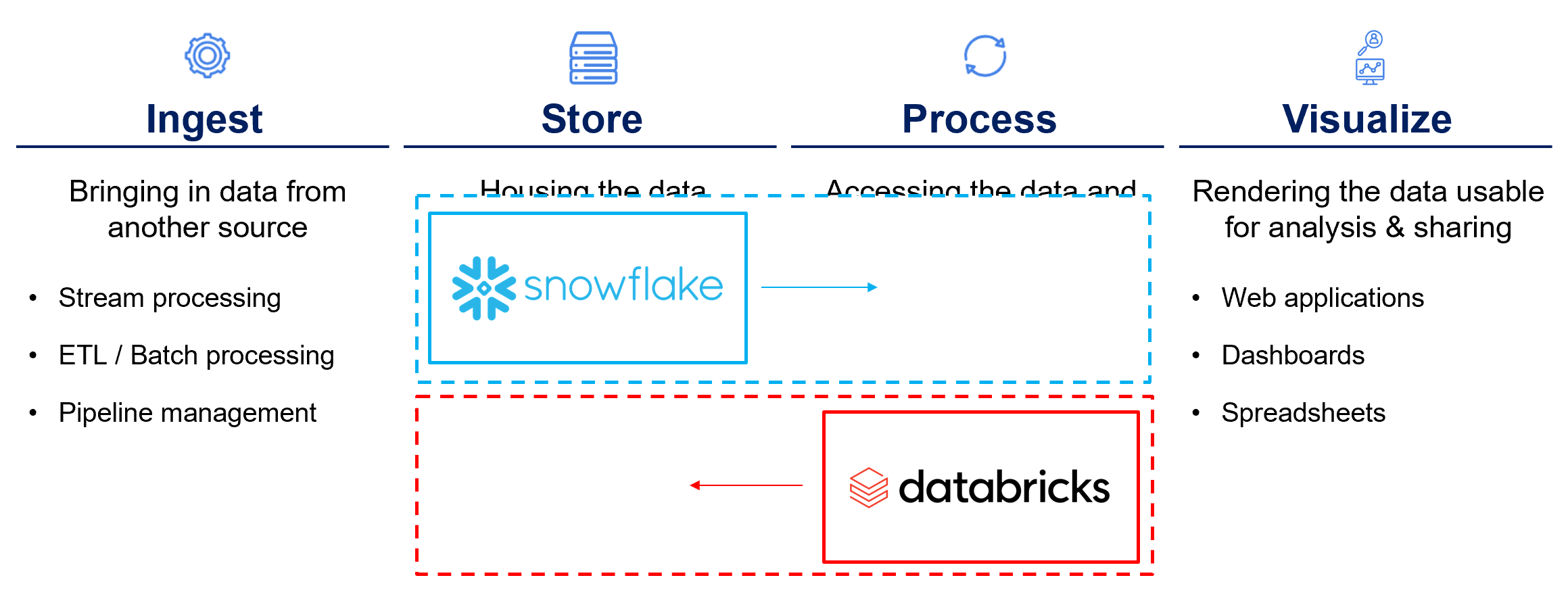
To bring some context to where Snowflake began, I think about the data stack as four buckets:

And for an even more basic Snowflake 101, see my Witty Wealth post.
Snowflake started off squarely in the store category — being the best storage layer it could possibly be for the modern world, because of its cloud-native architecture and its resulting ability to separate storage and compute.
Snowflake = Storage, and the very best storage around.
Databricks started as a Data Processing company.
Databricks has a very different founding story—while Snowflake was born from industry practitioners seeing the need for a better way, Databricks started off as an academic open-source project built at UC Berkeley.
The open source project was Apache Spark, a distributed computing framework that helps users run queries against schemaless data. By and large, Databricks started off helping companies more easily perform analytics & machine learning using Spark.

That puts them squarely in the ‘Process’ bucket in our framework.

Spark, with its material improvement over the previous market-leading open source project Apache Hadoop, became pretty popular pretty quickly—and Databricks became synonymous with Spark.
In fact, if you look into one of Databricks’ docs today, they still define themselves as ‘a managed platform for running Apache Spark’.

Similar to how Cloudera offers managed Hadoop, Confluent offers managed Kafka, and Imply offers managed Druid, and the list of managed Apache services companies goes on—Databricks offered managed Spark.
Pssssst, Databricks team, if you see this, might be time to update the above page with your latest positioning.
How it’s going:
Slowly but surely, anyone watching these companies will have noticed them creeping into one another’s territory.
In fact, around the time of Snowflake’s IPO last year, I wrote this:

A year ago, I actually thought that was a bit of a hot take that people might dispute, given the two companies’ different focuses—now, it seems incredibly obvious.
Snowflake: Storage ➡ Processing
Snowflake is still known first and foremost for being the best cloud data warehouse out there—it’s their bread and butter and is what got them to where they are today. That said, they’re pushing the boundaries on their ambitions, and they’re not secretive about it.
From the very top of their S-1:
Snowflake was started in 2012 to create a data warehouse built for the cloud. Beginning with our first customers in 2014, the response was beyond our expectations as we addressed major shortcomings of existing solutions and expanded from a data warehouse into an integrated cloud data platform.
While Snowflake is still *mostly* known for being the best cloud data warehouse out there, they’re making a run for more. Just look at the front page of their website:

While Snowflake depicts a multicolored swath of products above, they’re currently going hard at the ‘process’ bucket. See Snowpark as an example:

This puts them right into Databricks’ Process territory.
Databricks: Processing ➡ Storage
Databricks, which used to call itself a ‘Unified Analytics Platform on top of Apache Spark’, has now adopted a much broader moniker strikingly similar to that of Snowflake: The Modern Cloud Data Platform.

The first bold move for Databricks came in 2019 when they launched open source project Delta Lake — not to be confused with the real-world bodies of water named Delta, which are probably really struggling now in SEO.

Delta Lake is a storage layer that sits on top of data lakes to enable machine learning. Data lakes are a notoriously messy but effective data store—and Delta Lake makes sure the data coming in is reliable and ML-ready.
So, close enough to what they were doing with Spark — but now, rather than just processing the data, Databricks started interacting with the storage layer.
Ok, so Databricks has a Data Lake, Snowflake has a Data Warehouse… what on earth could possibly come next?

Because data people are the absolute worst at naming things, Databricks then coined the term ‘lakehouse’ (yes, AWS had previously used the term, but DB brought it mainstream), diving head-first into storage and attempting to combine the best of both worlds.
As an aside, Jamin Ball wrote a great piece on the Snowflake/DB and the lakehouse.
Now, Databricks sits squarely in Snowflake’s storage territory—and the areas the two companies cover are hugely overlapping:
Oh, and guess what? Snowflake now has a Lakehouse, too—because everyone gets jealous when their frenemy gets waterfront property before them.
The next SAP & Oracle?
All in all, these companies are becoming increasingly similar, and I’m excited to see how they morph and seek new avenues for growth as established companies.
As I squinted into the future and thought about the competitive dynamic, ERP giants SAP & Oracle came to mind.
While ERPs and Data Cloud Platforms are fundamentally different businesses, the more I started digging, the deeper I found the similarities between these pairs ran. Like chasing down clues in a treasure hunt, things got real fun, real quick.

The narrative was getting long, so I’m saving it for a Part Two to this piece to do it justice. I can’t wait to share it with you.
If you have any thoughts on the SAP/Oracle vs. Snowflake/Databricks comparison—or any great resources on the histories of SAP & Oracle—hit me up!
While I enjoyed this read, I think one key point missed is that databases don’t just store data, they do process it. The main processing paradigm in many including Snowflake is SQL, and it isn’t just used to get data out of databases for end user queries. In the analytic world huge volumes of grunt transformation, some of it quite sophisticated, are done in SQL. There are decades of history in optimising this stuff which means engineers have to worry a lot less about tuning than in other processing paradigms. Even in an ML pipeline perhaps 80-90% of what is done is work most easily done in SQL.
Of course not everyone likes working in that paradigm (though it’s interesting that almost every data lake alternative has felt the need to bolt on SQL-like processing) which is where the ability to use Scala and Java directly on or in Snowflake fleshes out the capability.
A critical part that needs to be kept in mind is ‘ownership of data’ - companies, businesses and entities want to own their data without having to move it around. A platform like Databricks provides that to those customers.